Abstract
We queried five major AI models (ChatGPT, Claude, Gemini, Perplexity, Grok) 10,800 times across 18 U.S. cities, 5 home service categories, 8 question phrasings, and 3 repeated waves to determine whether AI-powered search produces consistent, reliable business recommendations. It does not. The models recommend almost entirely different businesses from each other (Fleiss' kappa = −0.172; average pairwise Jaccard overlap = 5.6%). ChatGPT never returned the same answer twice across waves. Even slight changes in question phrasing significantly altered which businesses were named (Friedman p < 0.001). These findings demonstrate that AI-generated recommendations are neither stable nor convergent, with direct implications for businesses seeking visibility in AI-powered search and for consumers relying on these tools for local decisions.
Executive Summary: 10 Numbers That Tell the Story
- 23,068 unique businesses were named across 10,800 AI queries, and the five models can't agree on which ones matter.
- 5.6% overlap , the average proportion of businesses any two AI models have in common. They're not reading from the same playbook.
- Fleiss' kappa = −0.172 , the models don't just disagree, they actively anti-agree. Worse than random chance.
- 0.0% reproducibility for ChatGPT , of 720 unique queries asked 3 times, ChatGPT never returned the same answer twice. Not once.
- Only 4.2% of all queries produced identical results across three waves, across all models.
- Claude is the most consistent at 10.1% exact match and 56.7% majority match , and even that means 43% of the time it changes its mind.
- Question phrasing changes everything. Asking “who's the best plumber?” vs. “I need a plumber for an old house” produces only 17.5% business overlap (Friedman p < 0.001).
- Larger cities get 10% more recommendations per response (6.8 vs. 6.2 businesses), but city size doesn't fix the disagreement problem.
- ChatGPT names the most businesses (10,266 unique) while Grok names the fewest (2,088), a 5x difference in recommendation breadth.
- 16 of 20 businesses in a typical city+category appear in only one model's top 5. The AI models live in parallel universes.
Methodology
This study was pre-registered on OSF before data collection. The analysis plan, including all statistical tests and alpha thresholds, was filed in advance. No post-hoc modifications were made to the primary analyses.
Total: 5 models × 18 cities × 5 categories × 8 variants × 3 waves = 10,800 queries
Cities by Tier
| Tier | Cities |
|---|---|
| Large metros | Denver, Memphis, Boston, Birmingham, Minneapolis, Columbus |
| Mid metros | Portland ME, Scranton, Boise, Shreveport, Madison, Dayton |
| Small metros | Burlington, Elmira, Hilton Head, Hattiesburg, Waukesha, Terre Haute |
Statistical framework: Alpha = 0.05 with Benjamini-Hochberg FDR correction for all multiple comparisons. Effect sizes reported alongside significance tests. Both parametric and non-parametric alternatives computed. All code version-controlled; deterministic pipeline with fixed random seed (42).
Finding 1: The Models Actively Disagree
Research Question: Do AI models agree on which businesses to recommend?
No. They actively anti-agree. Fleiss' kappa across all five models was −0.172, indicating worse-than-chance agreement. A negative kappa means the models don't just fail to converge. They systematically recommend different businesses from each other.
The average pairwise Jaccard similarity was 0.056, meaning any two models share only about 5.6% of the businesses they name. Every pairwise Cohen's kappa was negative. The worst disagreement: ChatGPT vs. Gemini (k = −0.327). The highest overlap: ChatGPT and Gemini at 6.6%. The lowest: Claude and Perplexity at 3.5%.
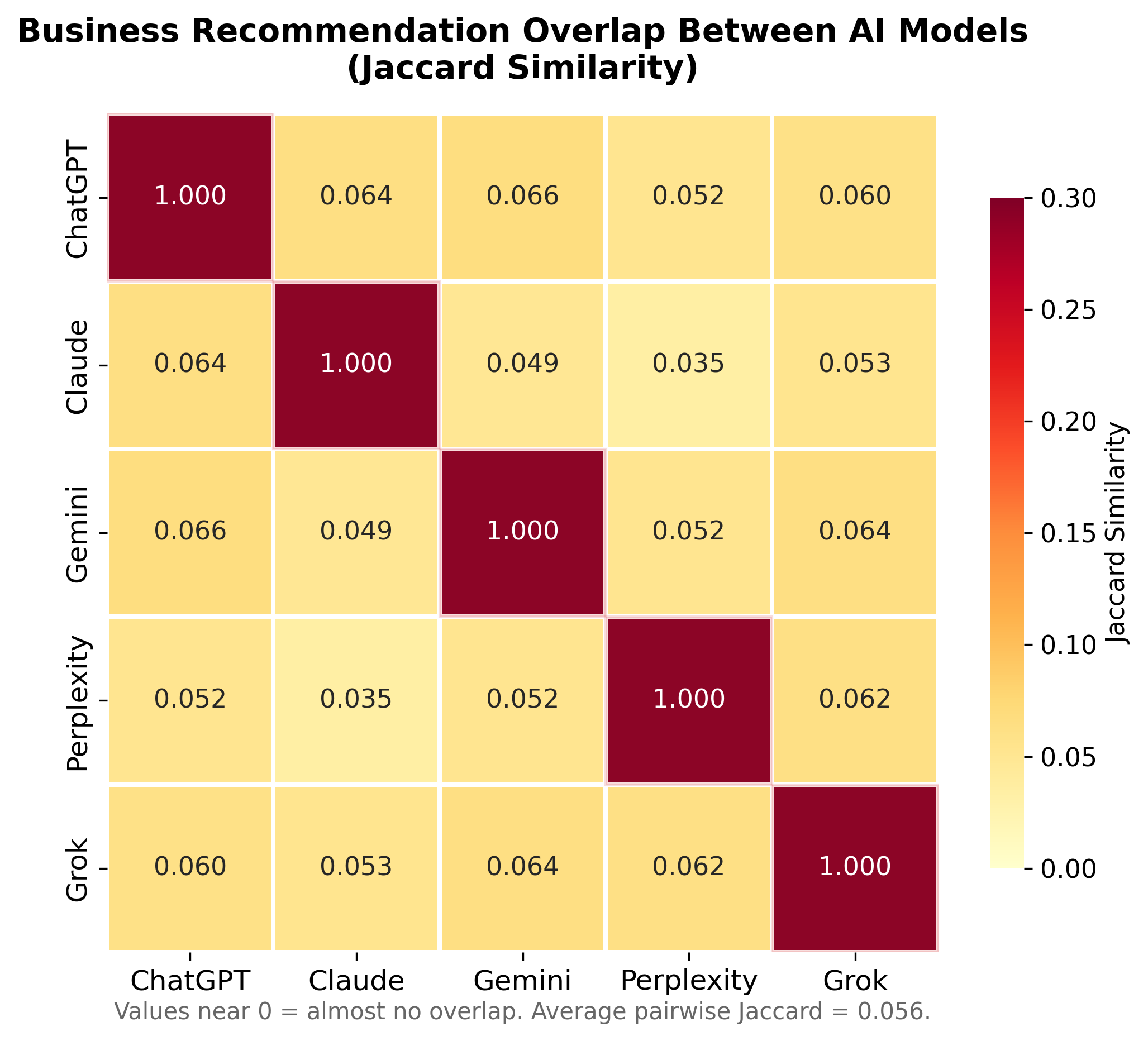
Businesses Named by Model
| Model | Unique Businesses | Share of Total |
|---|---|---|
| ChatGPT | 10,266 | 44.5% |
| Gemini | 6,335 | 27.5% |
| Claude | 5,111 | 22.2% |
| Perplexity | 3,606 | 15.6% |
| Grok | 2,088 | 9.1% |
What this means: A business optimized for visibility in ChatGPT has essentially no guarantee of appearing in Claude, Gemini, or any other model. There is no single “AI optimization” strategy. There are five different realities.
Finding 2: ChatGPT's Reproducibility Is 0%
Research Question: Are AI recommendations reproducible?
Barely. ChatGPT never returned the same answer twice. When we asked the exact same question three times across three waves, only 4.2% of queries returned identical business lists all three times.
| Model | Exact Match (3/3 waves) | Majority Match (≥2/3 waves) |
|---|---|---|
| Claude | 10.1% | 56.7% |
| Gemini | 5.0% | 51.9% |
| Grok | 5.3% | 22.4% |
| Perplexity | 0.4% | 13.1% |
| ChatGPT | 0.0% | 0.0% |
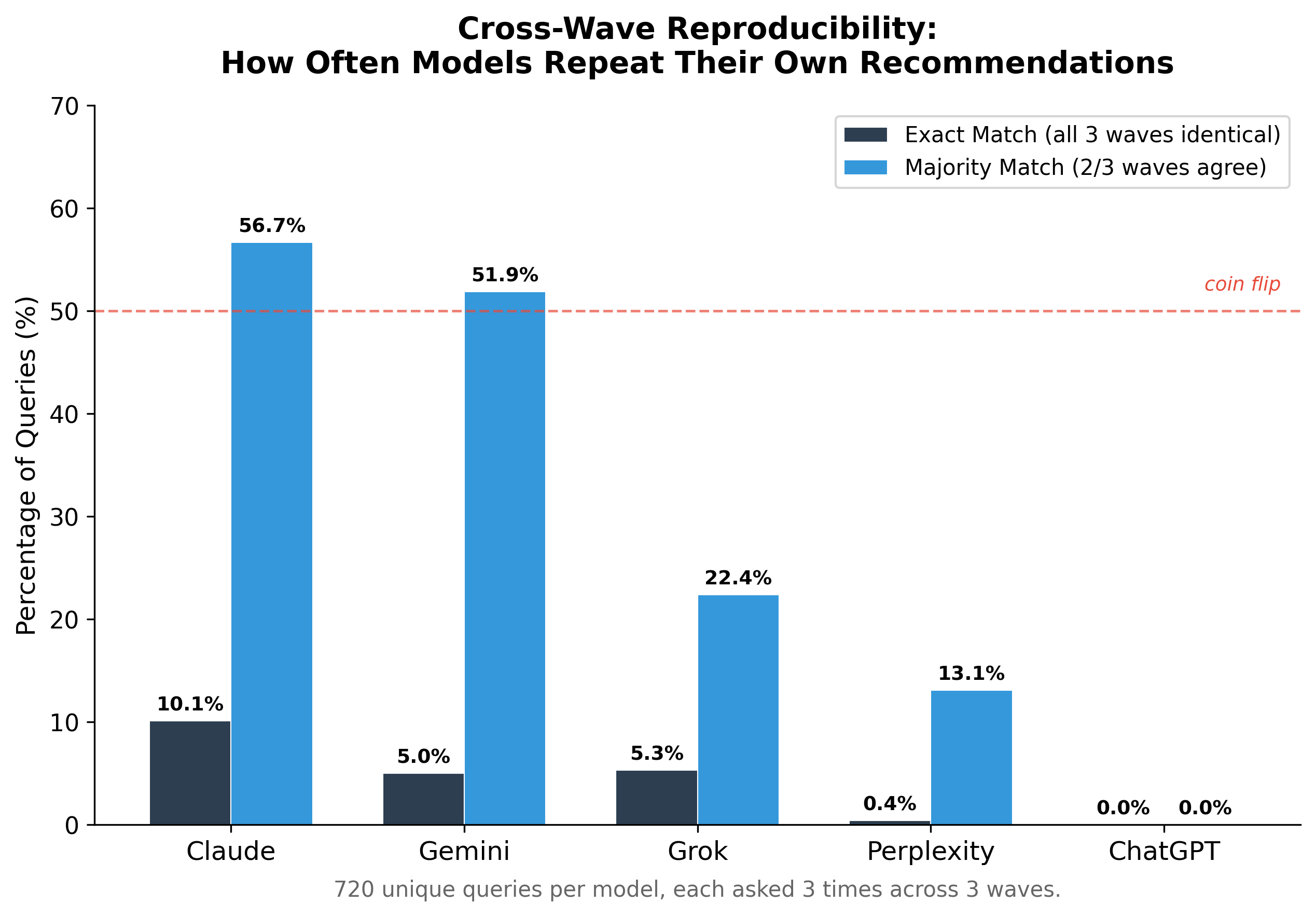
ChatGPT produced a completely different set of recommended businesses every single time, across all 720 unique queries, not one matched across all three waves, and not one even achieved 2-of-3 agreement. Claude was the most stable, but even Claude changes its mind 43% of the time.
What this means: AI recommendations are more like a slot machine than a phone book. The results change with every pull of the lever.
Finding 3: Question Phrasing Changes Everything
Research Question: Does question phrasing affect who gets recommended?
Dramatically. A Friedman test confirmed that query phrasing significantly changes which businesses are named (chi-square = 125.2, p < 0.001). Average overlap between any two phrasings: only 19.2%.
The more specific or situational the question, the more the recommendations diverge. Emergency queries (“24/7 plumber who can come tonight”) and niche queries (“best plumber for older homes”) produce the most unique recommendation sets.
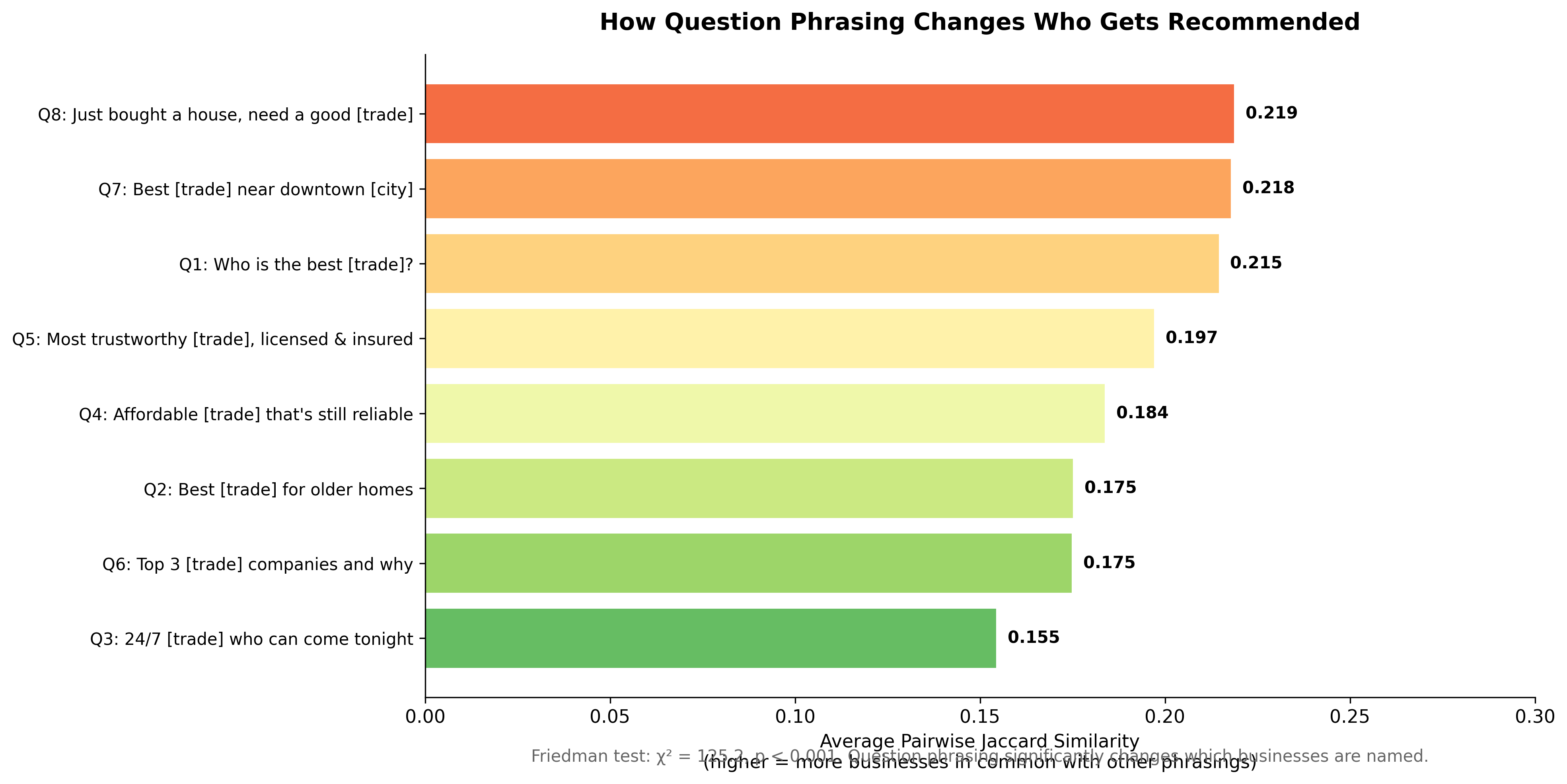
What this means: A business that appears when a consumer asks “who is the best plumber” may disappear entirely when the same consumer asks “I need a plumber for my old house.” The question itself is a variable as important as the answer.
Finding 4: Market Size Matters, Income Doesn't
Research Question: Do market characteristics affect AI recommendations?
City size matters. Income level does not. Large cities get ~10% more businesses named per response (F = 32.8, p < 0.001). But income tier has no significant effect on cross-model agreement (F = 1.9, p = 0.17).
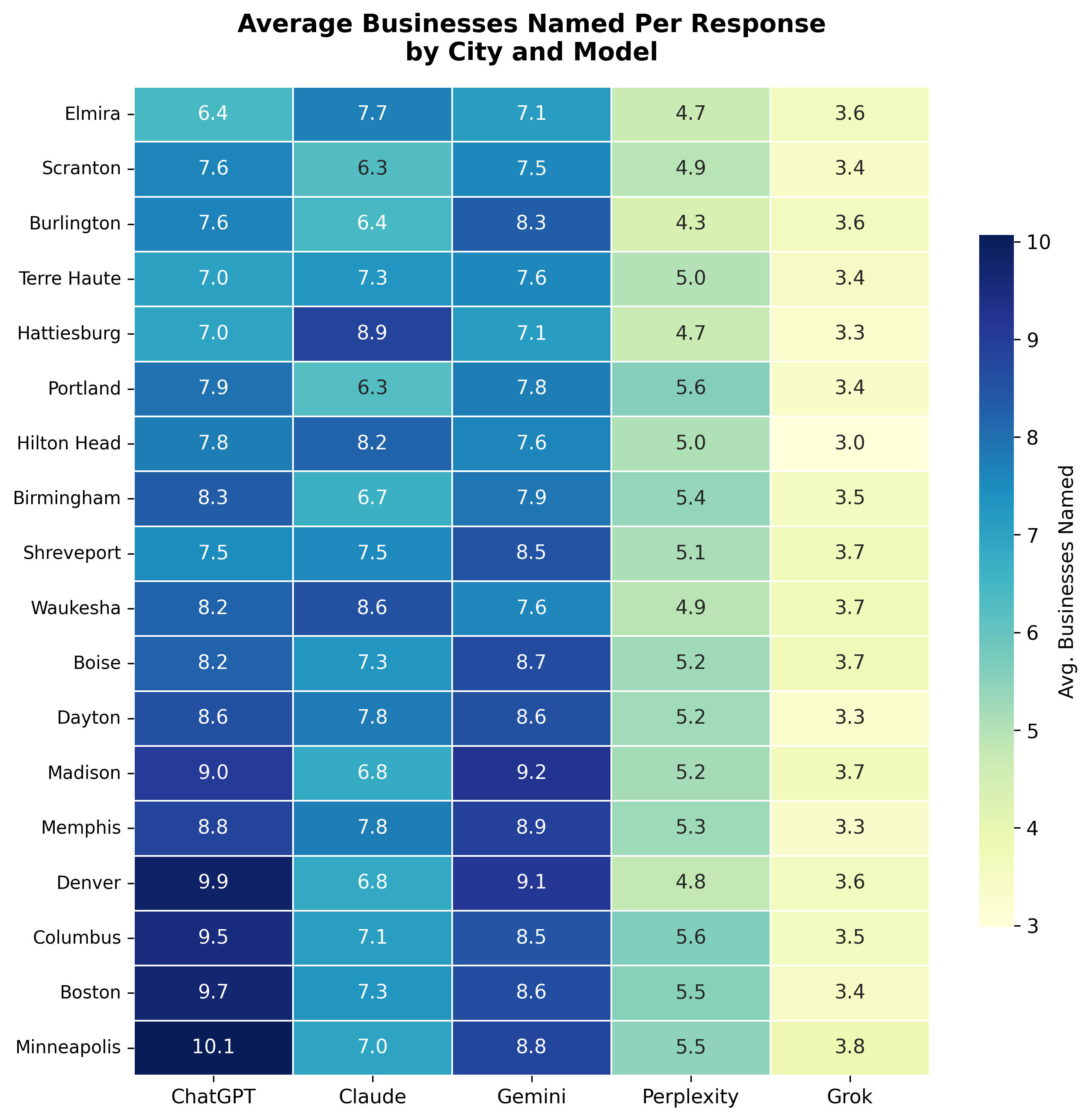
| City Tier | Avg Businesses per Response | Avg Models Agreeing |
|---|---|---|
| Large | 6.8 | 1.21 |
| Mid | 6.45 | 1.18 |
| Small | 6.19 | 1.17 |
What this means: Businesses in smaller markets face a thinner recommendation pool, but the fundamental problem, models disagreeing with each other, exists everywhere. Market size doesn't fix the divergence.
What This Means for Local Businesses
If you run a local service business and you're thinking about “getting recommended by AI,” here's what the data actually says:
There is no single AI optimization strategy.
The five models operate in parallel universes. What works for ChatGPT may be invisible to Claude. Any consultant selling you a one-size-fits-all “AEO package” either doesn't have data or isn't sharing it. The real work requires testing across models, tracking what actually moves, and adjusting.
Yesterday's recommendation is already gone.
With 0% reproducibility from the most popular AI model and under 5% across the board, a recommendation today means very little about tomorrow. The businesses winning this game will be the ones who monitor it continuously, not the ones who optimize once and walk away.
How your customer asks matters more than how you answer.
The same business appears or disappears depending on whether the customer says “best plumber” vs. “plumber for an old house.” You can't control how people ask. But you can ensure your business entity is rich enough to surface across different framings.
This study doesn't exist to sell you something. It exists because the data should be public. But if you're a local business owner looking at these numbers and thinking “I need someone who actually understands this”, that's what we do.
Limitations & Future Work
Temporal scope: All data was collected in a 3-day window (February 9–11, 2026). Longer intervals would likely show even greater instability. Longitudinal tracking is planned.
Category scope: Five home service trades only. Generalizability to other verticals, including legal, medical, restaurants, and retail, is untested but planned.
Phase 2 (pending): Tests 3–7 from the pre-registered analysis plan require business-level enrichment data (Google Places ratings, schema markup, domain age, review counts). These tests answer the core question: what predicts whether a business gets recommended? Phase 2 is designed and estimated at ~$1,400 in API costs for 23,068 businesses.
Parser accuracy: ChatGPT's unique markdown formatting required post-hoc correction, reducing total mentions from 81,363 to 71,835 (−11.7%). The correction was documented in the integrity log before statistical analysis.
Temperature settings: All models used temperature=0 for reproducibility (except GPT-5.2, which requires temp=1 per API limitation). Perplexity's search-augmented nature means results still vary.
Full Study Design
Pre-registration: OSF (osf.io/sr3fy), filed before data collection.
Design: 5 models × 18 cities × 5 categories × 8 query variants × 3 waves = 10,800 queries.
Models: ChatGPT (GPT-5.2-chat-latest), Claude (Sonnet 4.5, claude-sonnet-4-5-20250929), Gemini (2.5 Pro), Perplexity (Sonar Pro), Grok (4).
City stratification: 18 cities selected by population tier (large/mid/small), U.S. Census region, and income level (higher/lower). Each tier contains 6 cities spanning 4 regions.
Integrity: SHA-256 hash verification on all 10,800 raw JSON files. Deterministic analysis pipeline with fixed random seed (42). All code version-controlled in git.
Analysis pipeline: 10,800 raw JSON files → regex-based business name extraction (71,835 mentions) → canonical name matching (rapidfuzz, threshold 85) → statistical tests per pre-registered plan → automated executive summary generation.
Total cost: ~$105 in API fees. 100% completion rate. Zero failures across all three waves.
How to Cite This Research
Press & Citation Kit
Writing about AI recommendations, AEO, or AI search reliability? Use these resources. Attribution to The Midnight Garden and a link back to this page is appreciated.
Research Charts (High-Res)
All 5 figures from this study, ready for embedding in articles and presentations.
Pre-Registration
Full study design and analysis plan filed on OSF before data collection.
As Seen On / Discussed On
This research has been shared and discussed across multiple platforms. Follow the conversation:
Discussion threads will be linked here as they're published on Reddit, X, and LinkedIn. If you've written about or referenced this study, let us know and we'll add your link.
Want to Know If AI Recommends Your Business?
The data shows AI recommendations are unpredictable, inconsistent, and different across every model. We help local businesses navigate that reality, with data, not guesswork.
Contact The Midnight Garden